-
[데이터 엔지니어링 설치 방법 정리] Hadoop, spark, pyspark, anaconda (feat. windows 10)데이터 엔지니어링/Spark 2022. 6. 18. 17:41반응형
데이터 엔지니어링에 필요한 툴 설치 방법 정리
스파크 공부를 하기 위해서 먼저 다른 툴들을 설치할려고 했는데, 다른 툴들도 다 설치가 필요하더라 그래서 한꺼번에 정리하는 것이 좋을 것 같아 포스팅하게 되었다. 스파크는 java, python, scala를 모두 제공하는 프로그램이다. 그래서 스파크를 사용하기 위해서는 java(scala는 java기반으로 만들어진 언어)와 python을 구축해놓으면 된다. 다른 패키지들은 spark를 사용하여 데이터 처리를 하기 위해 사용되는 패키지들이여서 다운로드 받아 둔다. 그리고 이 환경을 구축하기 위해 모든 설치를 도와주는 툴이 있는데 이 anaconda이다 anaconda를 이용하여 설치 해보자.
Anaconda 다운로드
먼저 anaconda 설치 아나콘다 사이트에 들어가 자신의 os맡게 설치 하면 된다.
Anaconda | The World's Most Popular Data Science Platform
Anaconda is the birthplace of Python data science. We are a movement of data scientists, data-driven enterprises, and open source communities.
www.anaconda.com
그래서 실행하게 되면 아래의 팝업창이 뜨게 되고 그냥 next를 눌르면 설치가 완료 된다.

windows에서는 anaconda prompt라는 것이 생기며 실행 시키면 오른쪽과 같이 python이 자동으로 설치 되어있는 것을 볼수 있다.


스파크 다운로드 사이트
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
스파크 홈페이지로 이동한 다음 choose a spark release는 3.2버전 hadoop은 2.7을 선택해 준다. 그리고 바로 밑에 spark-3.2.1-bin-hadoop2.7.tgz를 클릭하여 다운로드 하는 사이트로 들어가서 다운로드 받으면 된다.

다운로드 하면 아래와 같이 tgz 파일 다운로드 되는데 압출을 풀고 c드라이브 안에 Spark폴더 생성 그리고 안에 압축푼 폴더를 넣어두면 준비 끝이다.

하둡 다운로드
하둡은 아래의 github에 들어가서 Download zip을 클릭하여 다운로드 해준다. 아래의 github이 hadoop 최신 버전을 다루고 있기 때문에 다운로드 하는 것이지 별다른 이유는 없다
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
github.com

하둡2.7.7버전안에 bin을 가져와 c드라이브 안에 Hadoop폴더를 생성 후 붙여 넣기 한다.


Pyspark 다운로드
anaconda prompt를 열어서 pip install pyspark를 하면 다운로드 된다.

환경 설정 하기
시스템 환경 변수에 아래와 같이 내용을 입력하고 변수를 만들고 path에 추가를 해주면 설정은 끝난다.

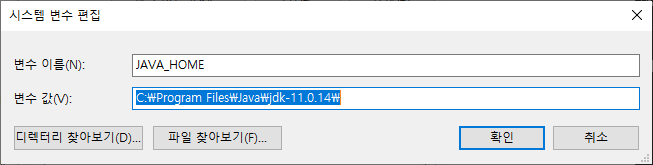



path에 방금 만든 것들 추가 확인
환경 설정이 끝났다면 anaconda prompt를 실행하여 pyspark, jupyter notebook, java --version 등 실행 해보면 확인이 가능하다.

 반응형
반응형'데이터 엔지니어링 > Spark' 카테고리의 다른 글
[Spark] Postgre의 데이터 JDBC 커넥터 활용하여 병렬 처리 해보기(feat, partitionColumn,lowerBound, upperBound, numPartitions) (0) 2023.02.12 [Apache Spark Job]구동 방식 이해하기 (Submit job, physical planning, stage, ) (1) 2022.08.03 [Apache Spark]Spark RDD의 한계점 및 Dataframe, SQL 등장, 최적화 원리 (0) 2022.07.11 [Spark]RDD 이해하기 (0) 2022.06.19 [Spark] 스파크란 무엇인가?(spark 등장배경, 쓰는이유, 빠른이유) (4) 2022.06.18