-
모던 데이터 엔지니어링 아키텍처 알아보기(data engineering loadmap)데이터 엔지니어링/데이터 엔지니어링 기본 2022. 7. 8. 21:37반응형
해당 글은 아래의 내용과 긱뉴스의 내용을 바탕으로 작성하였습니다.
You searched for modern data infra | Andreessen Horowitz
A new site for understanding the future, how tech shapes it, and how we build it.
a16z.com

데이터 인프라의 목적
- 데이터 기반의 의사 결정을 도와 주기 위해
- 서비스/제품을 데이터의 도움을 받아 향상시키기 위해
최신 데이터 인프라 구성요소
- source - 다양한 곳에서 나오는 데이터의 모든 것
- Ingestion and Transformation - ETL의 ET의 모든 영역을 담당
- Storage - ETL의 L(Load)에 해당하며 보통 Data Warehouse와 Data Lake로 나뉜다.
- Historical, Predictive - 적재한 데이터를 기반으로 분석하거나 미래 예측하는 모델을 도출
- Output - 모델들을 기반으로 분석한 내용을 화면에 보여 주어 의사결정에 도움이 되는 시각화를 해줌
Source - 발생하는 모든 데이터 소스
- OLTP - 정규화되고 트랜잭션 하나당 하나의 row데이터가 들어가는 것과 같은 형태의 트랜잭션 단위에 데이터 보관을 얘기 한다.

- CDC(Change Data Capture) - OLTP에 대한 데이터에 변화가 일어나면 후속으로 처리해주는 일련의 과정을 일컸는다. PL/SQL을 트리거 형식으로 호출 시키는 것이라고 보면된다
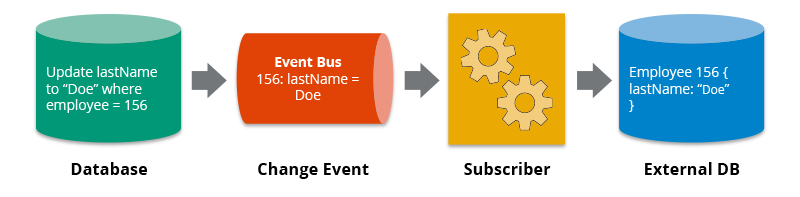
- Applications/ERP - 전사적 자원관리 라고 하는데 회사에서 하는 재무, 프로젝트 관리 등 회사에서 발생하는 모든 데이터나 CRM 등 application에서 생성되는 데이터를 말한다. 즉, 회사 내부의 데이터
- Event Collectors - 사용자가 만들어내는 데이터 (어떤 클릭으로 발생하는 Event 등)를 일 컫는다. Segment가 그 중 하나이다. 오픈소스는 SNOW PLOW, RUDDER STACK가 있다. 즉, 사용자 데이터

- LOGS - 데이터 발생의 로그 데이터
- 3rd Party APIs - 갑과 을의 형태에서 벗어난 제 3자의 형태를 말한다. 보통 솔루션을 만드는 회사는 결제 시스템이 없는데 결제시스템을 서드파티로 만드는 작업을 한다.
- File and Object Storage - 기본 파일과 오브젝트 형태의 데이터를 일컷는다.
Ingestion and Transformation
- Connectors - Source에서 발생하는 데이터를 데이터웨어 하우스나 데이터 레이크로 보내는 역할을 함 보통 DataWarehouse 적재 할 때 사용한다. 즉 ETL을 행하는 것이다.- Fivetran, Stitch, Matillion, Panoply(중소규모의 DataWareHouse를 품은 ETL툴) 등이 있다.

fivetran - Data Modeling 도구 - ETL을 하기 전에 자신에게 맞는 데이터 모델링을 테스트 형식으로 해볼수 있는 툴이다. dbt, LooKML이 있음 dbt는 개발자 혼자 쓰기에는 무료다.

dbt - WorkFlow Manager - 작업기반의 플로우를 만들 때 사용하는 툴이다.


우 prefect - Spark PlatForm - workflow와 연결이 되어있는데 작업기반의 잡을 실행해야하는데 분산처리를 하는 플랫폼이라고 보면된다. python lib과 batch engine을 품고 있는것이 spark platform이라고 보면된다.

- Event Streaming - 실시간 이벤트 처리 플랫폼이라고 보면 된다. 대표적으로 kafka가 있다. 메세지 큐라고도 하는데 메세지 큐만 하는 것이 아니라 메세지 큐 기반으로 다른 작업을 인지 시켜주는 부가적인 기능을 포함하는 플랫폼이라고 보면 된다.

- Stream Processing - 실시간으로 처리를 하기 위한 플랫폼이다. 대표적으로 Apache Flink와 Apache Beam과 같은 프레임워크가 있다.

Storage
- Data Warehouse - 데이터를 적재하는 장소라고 보면 된다. Connectors에서 봤듯이 원시 데이터를 그래도 보존하는 것이 아니라 분석가들이 사용하기 편리하게 모델링하거나 데이터를 변경하여 적재 해 놓은 형태로 구성하는 것이 Data Warehouse이다. 데이터 변경 하고 적재하는것에 Data Lake와 가장 큰 차이점을 보인다.

- Data Lake - 데이터 레이크는 원시 데이터를 그대로 적재 하고 그리고 나서 그 적재 데이터를 가지고 변경을 한다든지 실시간으로 분석하여 Output할 때 사용한다. 원시 데이터 그대로 보관하고 사용하는 개념으로 이해하면 좋다.
Historical, Predictive
- Data Science Platform - 데이터를 활용하여 분석하고 ai나 데이터 드리븐 의사결정에 필요한 데이터 분석 및 도출하기 위한 툴이다.
- Data Science and ML Libraries - ML , 딥러닝, AI등을 만들기 위한 것이다.
- Ad Hoc Query Engine - 광고 매출을 확인하기 위해 Query를 기반으로 분석하는 툴이다.
- Real-Time Analytics - 실시간 분석 툴이다.
Output
- Output에 해당하는 것은 다 같은 뜻으로 데이터를 DashBoard형식으로 보여주는 Looker, Tableau 등이 있고, Embedded Analytics DashBoard와 유사한다 이것을 어떤 솔루션에 넣어서 사용하는 분석 툴과 나머지 자신에 맞는 툴과 프레임워크를 만들어서 데이터 드리븐의 필요한 시각화를 해주는 작업을 일컫는다. 대표적으로 aws QuickSight, Google Looker, SalesForce Tableau, MS PowerBI, Databricks Redash등 이 있다.

좌-looker, 우 -redash 
좌 -tableau 우- powerbi 참고
Change Data Capture
Change data capture (CDC) is a software process that identifies & tracks changes to data stored in a database, such as inserts, updates, & deletes.
hazelcast.com
데이터 웨어하우스(Data Warehouse)와 데이터 레이크(Data Lake)의 차이
데이터 엔지니어를 하기 위해 준비하면서 앞으로 공부한 것들을 정리하고자 한다. 먼저 데이터 웨어하우스(Data Warehouse)와 데이터 레이크(Data Lake)가 무엇인지 또 그차이는 무엇인지 공부하고 정
loustler.io
반응형'데이터 엔지니어링 > 데이터 엔지니어링 기본' 카테고리의 다른 글
데이터 측면에서 웹에서 발생하는 데이터 종류 알아보기(Transaction, Metadata, Event, Log, Aggregation) (0) 2023.01.07