-
[kafka] KsqlDB란? - Ksqldb 주요 개념(push, pull query)과 kafka에서 사용하는 Streaming Proces데이터 엔지니어링/Kafka 2022. 7. 31. 11:39반응형
KSQLDB를 알기 전에 알아야 할 것 - Batch Processing vs Stream Processing
Ksql은 Streaming processing을 하기 위한 툴입니다. 그래서 Batch Processing하고 Stream Processing의 차이점을 알아야 하는데요. 아래와 그 차이점을 설명 해 놨습니다. 가장 큰 차이점은 데이터가 무한하다는 가정을 한다는 것인데, 이 부분이 KSQL과 기본 SQL에 차이가 나는 부분입니다.

KsqlDB란?
KsqlDB란 confluent에서 만든 Streaming processing용 툴입니다. Sql구문을 사용하여 Streaming Processing을 사용할 수 있으며, 클러스터 외에 새로운 KsqlDB용 서버 및 클러스터를 구축하여 사용할 수 있습니다. Ksql을 사용할려면 꼭 Kafka 클러스터가 있어야 합니다.
KsqlDB 서버
KsqlDB 는 툴이기 때문에 kafka 클러스터 외에 Ksql용 서버를 두어 사용하게 됩니다. Kafka클러스터에서 Producing,Consuming 하는 부분은 손대지 않습니다. 오직 Kafka클러스터에서 데이터를 가져와 다시 클러스터로 보내주는 아키텍쳐를 가지게 됩니다. 아래 그림을 보면 알 수 있습니다.

Ksql 설치 방법
Ksql 홈페이지를 가게 도면 아래와 같이 종류에 맞게 설치하는 방법이 나와 있습니다. 자신에게 맞는 방법을 선택하여 설치

주요 개념 - KStreams와 KTable
Streams는 순차적으로 들어오면 시퀀스 라고 합니다. Table은 현재 상태 기반의 최신값으로 업데이트 되어 보관된 데이터 라고 보면 됩니다.
예로, 아래 그림을 보면 체스판을 보게 되는데 체스판은 칸마다 번호가 존재합니다. x축으로 a,b,c,d ... Y축으로 1,2,3,4,5 이런식으로 좌표를 표시 할 수 있는데 Stream은 말의 이동경로를 시퀀스 형식으로 가지고 표시하는 걸 Stream이라고 하며, Table은 말의 현재 위치 상태만 가지고 있는 것을 의미를 합니다.
다른 예로, 오른쪽 그림을 보면 Robin이라는 사람의 이동 경로를 나타내게 됩니다. Robin이 이동하는 경로를 시퀀스로 보여주는게 Stream, Robin의 현재 상태만 보여주는게 Table입니다. 이 개념을 꼭 알고 넘어가야 Streaming Procssing을 접목 시킬 수 있습니다. 그리고 여기서 Stateless와 Statful의 개념이 나오게 됩니다.

주요 개념 - Stateless와 Stateful
State는 상태라는 뜻입니다. Stateless와 Stateful은 상태 기반으로 Processing을 하는 것이라고 보시면 됩니다. 아래 그림을 보면 Stateless는 상태에 영향을 주지 않는 연산을 의미한다고 하며, Stateful은 상태기반의 연산을 하는 group by나 count등을 의미 한다고 합니다. kstream과 ktable을 엮어서 생각해 보면 stream에서 key값 외에 value에 곱하기나 나누기 등의 연산을 하는 것은 state의 영향을 주지 않기 때문에 Stateless연산이고, 상태 기반으로 값이 없데이트 되는 Table이 Stateful 연산이 되고 난 이후의 데이터라고 보면 될것같습니다. Stateless operations과 stateful operations은 confluent 유튭채널에 자세히 나와 있으니 그것을 확인하기 바랍니다.

https://www.oreilly.com/library/view/hands-on-functional-programming/9781788831437/a0bdb458-2e17-4dbf-9016-08a256c5d6ef.xhtml 주요 개념 - Push와 Pull Query
Ksql은 sql을 사용하여 Processing을 한다고 하였습니다. 그래서 Sql을 사용하여 명령어를 날리게 되는데 여기서 sql구문으로는 stream과 table을 만드는데 한계가 있습니다. 우리가 아는 sql은 무조건 트랜잭션이 일어난 이후 데이터를 조회하는 용도 이기 때문에 stream을 신경 쓰지 않고 쿼리를 짜면 되었습니다. 하지만 Ksql은 Stream 무한한 데이터를 가정하고 sql을 짜야 하기 때문에 조금 다른 개념이라고 생각하고 sql을 짜야 합니다. 그 부분을 충족시켜 주기 위해서 KsqlDB 에서는 Push와 Pull Query가 존재 합니다.


좌 - push query, 우 - pull query -  왼쪽 그림이 Push Query입니다.들어온 내용을 확인하며 아래에 업데이트 된 내용이 있다면 계속해서 밀어 넣어주며 알려주게 됩니다. 오른쪽 그림이 Pull Query입니다. 오른쪽 그림에서 볼 수 있다 싶이 그때 당시의 데이터를 한번 조회하고 query가 종료 됩니다. push 와 pull을 구분하기 위해서는 Emit Changes절을 붙이면 됩니다. Push와 Pull query는 stream과 table 둘다에서 사용가능하지만. Create Stream과 table에서는 꼭 신경써서 사용할 수 있도록 연습이 필요 합니다. Stream은 연속적으로 들어오는 시퀀스, table은 상태기반으로 현재 상태의 값을 보관하는 table을 꼭 기억 하면 좋을 것 같습니다.
주요 개념 - Ksql Windowing 함수
streaming Processing에서는 꼭 알아야할 개념이 데이터가 무한하하고 가정한다는 것이 었습니다. 그래서 데이터가 들어와서 aggregation을 한다고 하면 Partition이 없기 때문에(데이터가 무한하기 때문에) aggregation이 이론상 할 수 없습니다. 그래서 필요 한 것이 바로 Windowing입니다. Tumbling, Hopping, Session 등 ksql에서는 3가지를 지원한다고 합니다. (추후에 업데이트 될 수 있음)
- Tumbling은 자신이 원하는 기간을 딱 정해서 partition을 나누는 것 10초 단위로 windowing(partition)이 된다고 하면 1~10, 11~20 초 이렇게 딱딱 나눠지는 것이라고 보면 됩니다.
- Hopping은 자신이 원하는 만큼의 duration을 정하는 것이라고 보면 됩니다.
- Session은 데이터가 들어오는 단위데로 Partition을 나누는 것입니다. 데이터가 stream형식으로 1~5초 들어왔다가 10초~60초까지 데이터가 들어왔다고 하면 session은 자동으로 1~5 10~60가지 windowing합니다.
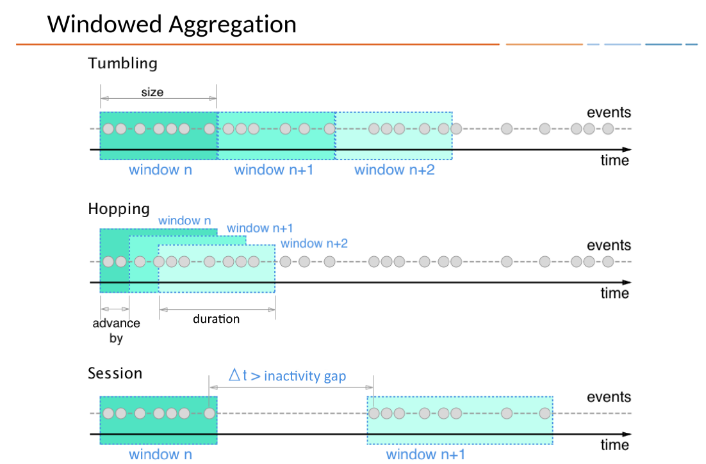
꼭 windowing에대한 개념을 알아야 streaming processing을 할 수 있습니다.
주요 개념 join
join은 ksql에서만 있는 개념은 아니지만 꼭 알고 넘어가야하는 개념입니다. 기본 적인 SQL에서 Table과 Table이 join되는 경우는 있지만, Stream과 join 되는 경우가 없기 때문입니다. 아래의 그림은 confluent에서 제시한 그림인데, 광고를 노출하고 click이 되는 stream에 대한 join입니다. 첫번째 그림은 View 광고가 노출되는 stream, click은 광고가 click되는 stream입니다. a가 광고가 노출 되고 클릭이 되었고, B는 광고가 노출이 되었지만, 10초 뒤에 클릭이 되고, 클릭이 된후 광고가 노출되지 않는 경우도 있을 수 있다고 가정했습니다.

위의 두 스트림을 조인을 걸어보면 아래와 같은 형식으로 나오게 됩니다. 광고가 노출 되고 클릭까지 이어진 경우 inner join, 광고가 노출 되었지만 클릭 된 것은 상관없는 경우 left join을 하면 된다고 합니다. 여기서 join을 걸때 window를 걸어 확인 하는 경우가 있을 수 있습니다. left stream-stream join그림을 보면 b의 경우가 그렇습니다. 광고가 노출 되고 클릭이 10초안에 이루어 져야 인정되는 join문이라면 클릭이 이루어 졌다고 한들 join문에서는 나오지 않게 됩니다.


이렇게 Stream processing에서의 기본 적인 join에 대한 개념을 알아 보았는데, 여기서 중요한 것은 Stream-Stream, Stream-table, table-table의 조인이 가능하다는 것입니다. 아래를 보게 되면 join종류가 지원되는 항목을 나열해 둔 것입니다.

https://docs.ksqldb.io/en/latest/developer-guide/joins/join-streams-and-tables/ stream-stream, stream-table, table-table을 join을 걸기 위해서는 꼭 데이터에 대한 이해를 바탕으로 join을 걸어야 할 것 같습니다.
주요 개념 - UDF(User Defined Function)
KSQL서버를 구축하면 기본적으로 제공하는 내장 함수가 있긴 하지만, 유저가 직접 정의하여 만드는 함수를 사용해야 할 때가 있습니다. ksqldb에서는 udf를 지원하는데 아래와 같은 형태로 import하면 된다고 합니다. maven, gradle, sbt등으로 library를 import 하고 그 값을 가지고 오른쪽같이 함수명과 같이 annotation을 이용하여 정의 합니다. 그리고 jar파일로 export한다음 ksqlDB에 ext??(plugin??)라는 폴더에 넣어 두어 sele문에서 가져다 사용한면 된다고 합니다. 필자는 maven에 import하려고 했으나 maven repository에 있는 내용이 import가 되지 않아 사용해보지는 않고 알아만 두었습니다.



이번 글은 ksql이란?, 설치방법, 주요개념을 이해하는 글이었는데 솔직히 저도 보고 나서 생각을 해봤을 때 이해가 되지 않았습니다. 그래서 다은 글 부터는 실제로 이것을 직접 도커로 설치해 보고 모델링도 해보고 실행해보는 예제를 포스팅 할 예정입니다. 모든 분들에게 도움이 되었으면 좋겠습니다.
실습
참고문헌
https://www.confluent.io/blog/crossing-streams-joins-apache-kafka/ksqlDB: The database purpose-built for stream processing applications.
The latest features, supported by the community.
ksqldb.io
Time and Windows in ksqlDB - ksqlDB Documentation
Time and Windows Important This page refers to timestamps as a field in records. For information on the TIMESTAMP data type, see Timestamp types. In ksqlDB, a record is an immutable representation of an event in time. Each record carries a timestamp, which
docs.ksqldb.io
반응형'데이터 엔지니어링 > Kafka' 카테고리의 다른 글
[Kafka] KsqlDB 실습하기 - create Kstream, Ktable (0) 2022.07.31 [Kafka] ksqldb 실습환경 구축해보기 (0) 2022.07.31 [Kafka]kafka 필수 개념인 Topology와 Streaming processing 종류 알아보기- , Kpub/sub, Kstreams, KsqlDB의 차이점 (0) 2022.07.22 [Apache Kafka]구성요소 이해하기(Cluster, Broker, Topic, Partition, Producer, Consumer, Zookeeper) (0) 2022.07.14 [Apache Kafka]Kafka가 만들어진 이유를 알아보자(개발 이유, 쓰는 이유 등) (0) 2022.07.11