-
[Kafka 원리]Kafka Consumer 동작 원리 이해하기 (Consumer group, rebalancing, commit_offset, option, fetch 튜닝, message ordering(순서))데이터 엔지니어링/Kafka 2022. 11. 6. 21:54반응형
목차
- consumer란?
- consumer offset
- Consumer는 어떤 메시지를 읽을 수 있을까?
- consumer group
- Consumer 메세지 읽기 옵션
- Consumer Rebalance
- Consumer Group간 Rebalancing 옵션
- 그러면 언제 언제 Rebalancing 될까?
- Consumer Message Ordering(메시지 순서 조작하기)
Consumer란?

- broker 로컬에 저장 되어있는 메시지(log Segment)에서 메시지 내용을 가져와 사용하는 사용자 역할을 하는 애플리케이션이다.
- 컨슈머는 반드시 컨슈머 그룹에 속해 있어야 한다.
- 컨슈머 그룹은 하나 이상의 컨슈머가 존재한다.
- consumer를 구성할 때 bootstrap.servers, group.id, key.deserializer및 value.deserializer를 필수로 작성하여야 한다.
consumer offset
- Commit 된 메세지를 Consumer group에서 consume 해서 메시지를 사용하게 되는데 이때 어디까지 읽어갔는지에 대한 위치 정보를 보관하는 것이 consumer offset이다.
- consumer offset은 consumer group별로 관리 되어 다른 consumer group과 consumer offset이 충돌 나지 않는다.
- consumer offset 정보는 broker topic에 저장 된다. consumer가 다운되어도 정보가 살아지지 않는다.
Consumer는 어떤 메세지를 읽을 수 있을까?
https://rongxinblog.wordpress.com/2016/07/29/kafka-high-watermark/ - Consumer는 메세지를 소비할 때 replica를 하지 않은 메시지는 가져오지 않게 설계되어있다. 메시지를 replica를 하지 않고 broker가 장애가 발생하면 메시지의 오류가 발생할 수 있기 때문 그래서 High Watermark가 된 메시지만 가져올 수 있습니다.
- Last Commit은 offset이 커밋 된 내용이고, Current Position은 현재 consumer가 가져간 message의 현재 위치를 나타내는 것입니다. current Position에서 consumer가 commit을 해주어야 commit offset이 변경이 됩니다.
- enable.auto.commit = true로 설정하여 poll에의 해 5초마다 offset을 commit 하게 할 수 있습니다.
- enable.auto.commit=false로 설정하면 consumer application에서 동기와 비동기로 나누어 커밋을 하는 로직을 만들어 주어야 합니다. 자세한 내용은 여기 참조
Consumer group

- consumer는 broker에서 Partition별로 메세지를 가져오는 용도로 활용된다.
- consumer group은 group.id 속성으로 구분 되어 group인지 아닌지 판단된다.

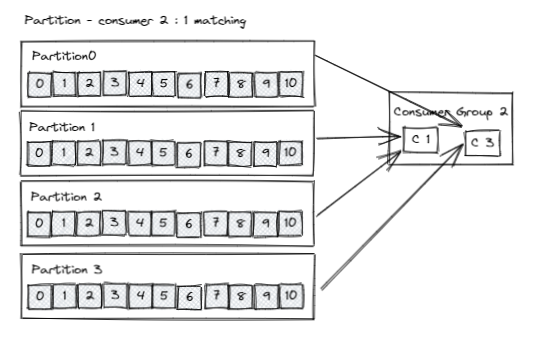

- Partition은 동일한 consumer group안에 하나의 consumer에게만 매칭 된다.
- 동일한 consumer group안에 Consumer는 다수의 Partition의 메시지를 받을 수 있다.
- 다수의 consumer group이 있다면 consumer group 별로 consumer offset이 관리되므로 동일한 내용의 메시지를 소비할 수 있다.
- 파티션에 연결 되어있던 컨슈머가 장애가 발생되면 자동 리밸런싱 되어 다른 컨슈머로 파티션이 할당된다.
Consumer 메시지 읽기 옵션
Consumer는 얼마나 많은 양을 가져와야 할까? Consumer가 읽는 량이 작다면 Fetch(메시지 읽기)가 반복적으로 일어나서 성능에 안 좋게 될 것입니다. 이를 해결하기 위해 많은 옵션이 있지만, 아래의 내용이 처리 성능을 높이는 데 사용됩니다.
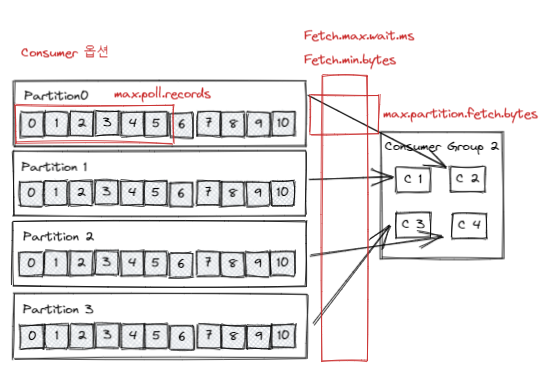
옵션 설명 fetch.max.bytes 한번에 가져 올 수 있는 최소 크기, 다 채워지지 않는다면 기다린다. max.partition.fetch.bytes 파티션당 가져올 수 잇는 최대 크기 max.poll.records poll 가져오는 최대 레코드 수 fetch.max.wait.ms 이 설정 값보다 적은 경우 요청에 대한 응답을 기다리는 최대 시간 Consumer Rebalance
Partition이 장애 발생하면 replica를 이용하여 broker에 메시지 보존하는 전략을 가지고 있다. 그러면 Consumer application이 장애 발생하면 Partition에서 받아오는 메시지를 어떻게 처리를 할까?


그림상 C4가 장애가 발생하여 메시지를 받지 못한다고 하면 오른쪽 그림 처럼 다른 컨슈머가 메세지를 받을 수 있도록 Rebalancing 된다.
Consumer Group 간 Rebalancing 옵션
위에는 Consumer가 장애 발생 시 Rebalancing 되는 것을 알아보았는데 그러면 Consumer Group은 어떤 기준으로 Rebalancing을 진행할까?
- Consumer Group은 Consumer가 살아 있는지 아닌지를 확인하기 위해서 일정 주기마다 Heartbeat를 보내어 생존 여부를 확인한다.
- heartbeat를 보내면 컨슈머가 active상태가 되는 것이다.
- heartbeat를 보내지 않고 계속 기다리고 있는 시간의 최댓값을 session으로 정해 줄 수 있다. 아래 옵션으로 Consumer가 Group안에서 살아 있는지 아닌지를 파악할 수 있다.
옵션 설명 group.id 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자 heartbeat.interval.ms 컨슈머 그룹이 active상태임을 나타냄. session.timeout.ms 보다 낮은 값을 설정해야함, 일반적으로 1/3 (session.timeout.ms)로 설정 session.timeout.ms 컨슈머가 종료된 것인지 파악하는 시간. 이 시간까지 하트비트를 보내지 않는다면 컨슈머가 종료 된것으로 판단하고 리밸런싱 한다. 그러면 언제 언제 Rebalancing 될까?
아래 3가지 경우가 대표적인 Rebalancing 되는 기준이다.
- Consumer가 Consumer group에서 없어졌을 때
- 새로운 Consumer가 Consumer group에 편입되었을 때
- Consumer Group이 Topic의 정보가 변경되었을 때(보통 Partition 증가)
Consumer Message Ordering(메시지 순서 조작하기)
이전 글에서 Producer가 Broker에 메시지를 보낼 때는 Key값으로 어떤 Partition에 보낼지 정할 수 있다고 하였음. 그림상으로 Key값이 없으면 Partitioner에 의해 Round robin방식으로 전달돼 거고, Key값이 있으면 해당 Partition으로 전달됨
- Consumer는 Partition에 어느 위치까지 읽었는지는 offset으로 알 수 있음
- 하지만, 메시지를 소비하는 입장에서는 위치를 나눠서 가져올 수 없음

Consumer는 메세지를 소비할 때 순서를 보장하고 싶으면 어떻게 해야 할까?

- 첫 번째 방법 - Partition 1 개를 생성해서 모든 메시지를 받으면 메세지를 보장할 수 있지만 처리량이 저하하고 확장성이 없어짐 병렬 처리가 되지 않기 때문에 속도도 떨어짐
- 두 번째 방법 - Consumer Group 안에 consumer들을 설정하여 Partition당 1:1 매칭을 할 수 있다고 하였는데 Partition 숫자 : Consumer 숫자 이렇게 1:1 매칭을 해주어 Key값 별로 들어온 Partition을 매칭 하여 메시지 순서 보장을 해줘야 함
Consumer 주요 옵션
아래 옵션을 설정하여 어떻게 메시지를 받아 올지 설정할 수 있다.
옵션 설명
옵션 설명 fetch.max.bytes 한번에 가져 올 수 있는 최소 크기, 다 채워지지 않는다면 기다린다. group.id 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자 heartbeat.interval.ms 컨컨슈머 그룹이 active상태임을 나타냄. session.timeout.ms 보다 낮은 값을 설정해야함, 일반적으로 1/3 (session.timeout.ms)로 설정 max.partition.fetch.bytes 파티션당 가져올 수 잇는 최대 크기 session.timeout.ms 컨슈머가 종료된 것인지 파악하는 시간. 이 시간까지 하트비트를 보내지 않는다면 컨슈머가 종료 된것으로 판단하고 리밸런싱 한다. enable.auto.commit 백그라운드로 주기적으로 오프셋을 커밋 auto.offset.reset earliest : 가장 초기의 오프셋값으로 설정, lates : 가장 마지막의 오프셋 값으로 설정, none : 이전 오프셋값을 찾지 못하면 에러 group.instance.id 컨슈머의 고유 식별자. static 멤버로 등록되어 불필요한 리밸런싱을 하지 않음 isolation.level 트랜잭션 컨슈머에서 사용되는 옵션, max.poll.records poll 가져오는 최대 레코드 수 partition.assignment.strategy 파티션 할당 전략 default = range fetch.max.wait.ms 이 설정 값보다 적은 경우 요청에 대한 응답을 기다리는 최대 시간 참고 문헌
https://www.popit.kr/kafka-consumer-group/
https://www.conduktor.io/kafka/kafka-consumer-groups-and-consumer-offsets
https://joooootopia.tistory.com/30
https://www.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch04.html
https://madplay.github.io/post/kafka-producer-consumer-options
https://medium.com/walmartglobaltech/rendezvous-with-kafka-a-simple-guide-to-get-started-48db3b921cc
https://rongxinblog.wordpress.com/2016/07/29/kafka-high-watermark/
반응형'데이터 엔지니어링 > Kafka' 카테고리의 다른 글
[Kafka 원리] replication-factor, ISR , 리더 에포크, 가용성 알아보기 (0) 2022.11.06 [Kafka 원리] Kafka Broker 메세지 저장 방식Cluster(broker), partition, segment 기본 개념 및 옵션 (0) 2022.11.05 [Kafka 원리]Kafka Producer 처리 방식 이해하기(feat. 튜닝, batch, linger, acks, compression, message send주기, message 순서 보장) (1) 2022.11.05 [Kafka] KsqlDB 실습하기 - create Kstream, Ktable (0) 2022.07.31 [Kafka] ksqldb 실습환경 구축해보기 (0) 2022.07.31
