-
Hive 테이블 문제점 및 대체제 알아보기 Hudi vs Iceberge vs delta lake 이해하고 비교해보기데이터 엔지니어링/Hive 2022. 11. 27. 17:20반응형
이전 글에서 HQL을 사용해보았고 Compaction에 대해 포스팅을 할려고 했으나 compaction 시 에로사항이 많아서 포스팅을 하지 못한다고 판단하였고 대신에, hive 테이블의 문제점과 대체제에 대해 알아보는 시간을 가져보면 좋을 것 같아 이 글을 작성하게 되었습니다.
Hive에서는 Hive Table을 만들어서 데이터를 관리하고, Hive Query을 이용하여 데이터를 조회하게 되는데, 여기서 오는 문제점에 대해 간단하게 알아보겠습니다.Hive Table 구조
Hive는 데이터를 관리할때 메타스토어(RDB) + 데이터(HDFS안에 있는 실제 데이터 파일) 로 나뉘어서 관리 됩니다. DB에서 파일이 어디에 있는지 어떤 데이터를 추출해야하는지 스키마나 파티션 이런 정보들을 관리하고 실제데이터는 HDFS나 S3등에 적재 되어있습니다.

https://data-flair.training/blogs/hive-data-model/ Hive Table의 문제점
Hive Table을 사용할 때 아래와 같은 문제점이 발생했다고 합니다. 이런 정보는 Line Data Platform 영상에서 확인 할 수 있습니다.
- ACID 완벽하게 지원되지 않는 문제 - Hive Table은 기본적으로 HDFS를 사용하므로 Update를 지원하지 않기 때문에 오는 Transaction 처리 문제 Transaction은 일부 지원하지만 완벽하게 지원되지 않습니다.
- 병목현상 - Hive는 메타스토어라는 메타데이터 저장소를 RDB를 활용하여 구축하고 실제 데이터는 HDFS에 저장하고 관리한다고 하였는데 이로써 오는 데이터가 쌓일 수록 RDB의 성능 문제 (RDB의 관리가 필요함)
- 스키마 확장성 미지원 - 메타데이터를 직접 관리 하지 않기 때문에 스키마를 확장 할 수 없다는 점(파티션이나 스키마 다시 지정하고 싶다면 테이블을 지우고 다시 생성해야 함)
- 파일 관리 시스템 - 데이터 조회 시 RDB(메타스토어)의 메타데이터 조회 및 HDFS의 실제 데이터 파일에서 파일의 데이터를 추리고 반환해주게 되는데 HDFS의 파일 목록이 쌓일수록 latency 문제가 발생
- latency 문제 - 위에 latency 문제는 compaction으로 관리 하지만 compaction시에 table을 일시적으로 사용할 수 없다는 점
자세한 문제점은 이 동영상을 참고 해주세요
위와 같은 문제점을 해결하기 위해 많은 형식의 테이블들이 나오고 있습니다. 그중에 크게 3가지가 있습니다. Uber에서 만든 hudi, Netflix에서 만든 iceberg, databricks에서 지원하는 delta lake가 있습니다. 이 3가지의 내용을 간추려 보도록 하겠습니다.Apache Hudi
먼저 Hudi는 Hadoop Update, Delete, Insert의 줄임말입니다. 2016년 Uber에서 만들어 졌고 Uber의 특성상 스트리밍 프로세싱에 더 중점을 두고 만들어 졌다고 합니다.
Hudi의 주요 장점
- ACID 지원
- 동시성 제공 - 읽고 쓰기중 데이터 변경 가능
- 메타데이터 확장 가능
- 스트리밍에 특화되어 증분 파이프라인이라는 새로운 패러다임을 개척했음
- 모든 변경 사항을 추적하고 변경 스트림으로 노출하여 CDC와 트랜잭션에 특화 되어있음
- 인덱싱을 지원하고 인덱싱을 사용하면 변경 스트림을 보다 효율적으로 활용 할 수 있다고 함
지원하는 테이블 형식
Copy On Write - 복사하여 쓰기 (hive테이블과 유사)
- Commit마다 변경 처리 되는 방식이다.
- Commit시 새로운 파일이 생성된다.(Parquet으로만 관리)
- 데이터 변경이 자주 일어나지 않지만 Select 시에 유리한 테이블 형식

https://hudi.apache.org/docs/next/table_types#copy-on-write-table Merge On Read - 읽을 때 병합
- commit시 delta log에 내용을 저장하고 새로운 파일이 생기지는 않는다.
- Parquet(열 기반) + Avro(행 기반)으로 commit 내용과 데이터가 보관된다.
- 일반적으로 transaction이 많이 일어나는 테이블에 사용됩니다.
- 일정 주기 마다 compaction이 실행 되어 최신 데이터를 조회 할때 성능에 문제가 없게 합니다.
- 조회 유형은 두가지가 있는데 일반 쿼리 시에는 compaction된 내용을 기준으로 바로 조회하고, 과거데이터 쿼리시 compaction기준으로 해당 지점 까지 merge후 보여 줍니다.
- compaction(압축)이 일어날 때 새로운 파일이 써집니다.(Parquet파일)

https://hudi.apache.org/docs/next/table_types#copy-on-write-table Apache Iceberg
Netflix에서 개발되어 2018년에 인큐베이팅 프로젝트를 거쳐 2020년 정식 오픈소스 프로젝트로 인큐베이팅을 졸업했다고 합니다. Apache Iceberg는 페타바이트 규모의 테이블을 위해 설계된 개방형 테이블 형식으로 설계 되어 모든 파일 포맷을 관리 구성 및 추적하는 방법을 결정하여 snapshot방식으로 파일을 관리한다고 합니다.
Iceberg 주요 장점
- ACID 지원
- 동시성 제공 - 읽고 쓰기 중 데이터 변경 가능
- 메타데이터 확장 가능 - snapshot방식이라 유동적으로 가능
- 다른 테이블 포맷과 달리 물리적 데이터는 ORC, Avro, Parquet 등의 형식을 지원하여 확장성이 좋다.
- snapshot방식을 체택하였고, snapshot을 이용 할 때 영구 트리 구조를 사용하여
- snapshot방식으로 메타데이터가 유동적으로 관리 되기때문에 스키마 변경 가능, 파티션 변경 가능, time travel , 버전 별로 롤백을 지원함
지원하는 테이블 형식 - snapshot
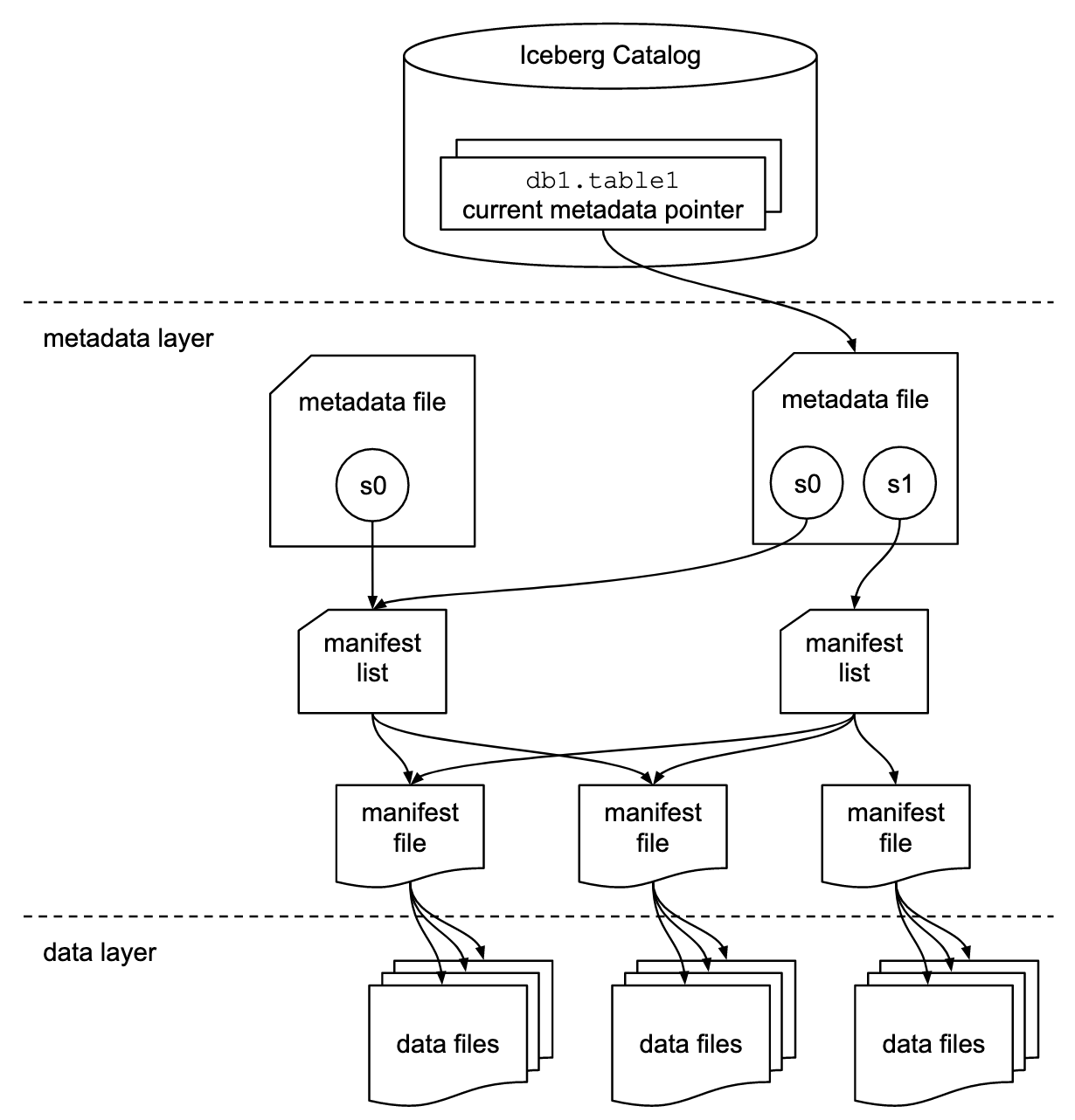
https://docs.dremio.com/software/data-formats/apache-iceberg/ snapshot은 특정 조건을 직어 둔다는 의미입니다. 위의 그림에서 보면 3개의 계층으로 나뉘어져 있습니다.
- Iceberg Catalog Layer - 현재 메타데이터 포인터의 위치를 찾기 위해 이동하는 곳 지정된 테이블에 대한 데이터를 읽거나 쓸 위치를 식별하는데 도움이 됨 현재 쿼리의 해당하는 메타데이터 파일을 식별 하는 것으로 사용
- Metadata Layer - 메타데이터 파일, 매니페스트 목록 및 매니페스트 파일의 세가지 구성 요소로 구성됨, 메타데이터 파일에는 테이블의 스키마, 파티션 정보, 스냅샷 및 현재 스냅샷에 대한 정보가 포함되어있어 쿼리에서 원하는 데이터를 빨리 찾아 갈 수 있도록 도와줌
- Data Layer - 각 매니페스트 파일은 파티션 구성원, 레코드 수, 열의 하한 및 상한에 대한 세부 정보가 포한된 데이터 파일의 하위 집합을 추적함.
Apache Delta Lake
Delta Lake는 databricks에서 정식적으로 사용하는 테이블 포맷입니다. 오픈소스이며 Spark와 호환되어 사용하고 테이블을 관리하는 파일 포맷은 Parquet파일로 관리됩니다. 오픈소스 이지만 모든것이 오픈 된건 아니고 databricks와 연동 된 부분은 private하게 관리 된다고 보면 된다.
Delta Lake 주요 장점
- ACID 지원
- 동시성 제공 - 읽고 쓰기 중 데이터 변경 가능
- 메타데이터 확장 가능 - snapshot방식이라 유동적으로 가능
- spark와 호환이 좋아 spark streaming, spark structure등 사용이 가능하다.
지원하는 테이블 형식 - Delta log
- _delta_log라는 폴더에 트랜잭션이 일어나면 새로운 json과 Parquet파일이 생성 됨
- 트랜잭션이 일어나면 버전이 생성되며 버전은 Checkpoint에서 관리됨
- 버전별로 schema및 메타데이터가 관리됨
- 데이터도 parquet파일로 관리가 됨
- 이런 버전 넘버링으로 Time Travel을 가능하게 해줌
- 쿼리를 날릴때도 delta_log폴더에서 쿼리에 해당하는 checkpoint를 읽고 이내용으로 파일의 데이터를 읽어들여 반환해줌

https://www.youtube.com/watch?v=Wx8G08jaedo 간단하게 비교하기
- 공통적으로 acid, 동시성, time travel 등 지원(hive에서는 없는 기능이 많음)
- Delta lake는 성능이 최대 효율 spark 100퍼 호환, databricks에서 관리하므로 cloud 3사에 호환이 됨
- hudi는 streaming에서 최대 효율 spark 호환되며 athena등에서도 호환되어 확장성이 있음
- iceberg는 많은 파일 포맷 지원, spark와 호환되고 flink나 다른 툴에 호환이 좋음 확장성이 있음

https://www.youtube.com/watch?v=Wx8G08jaedo
참고문헌
공통
https://data-flair.training/blogs/hive-data-model/
https://www.onehouse.ai/blog/apache-hudi-vs-delta-lake-vs-apache-iceberg-lakehouse-feature-comparison
hudi
https://sheerheart.tistory.com/entry/Apache-Hudi-소개-HDFS-upsertdelete
https://www.slideshare.net/NishithAgarwal3/hudi-architecture-fundamentals-and-capabilities
iceberg
https://www.youtube.com/watch?v=7y9gNwqLNtU
https://docs.dremio.com/software/data-formats/apache-iceberg/
https://medium.com/expedia-group-tech/a-short-introduction-to-apache-iceberg-d34f628b6799
delta lake
https://learn.microsoft.com/ko-kr/azure/databricks/delta/
https://data-engineer-tech.tistory.com/54
https://www.youtube.com/watch?v=de-6a6Bfw6E&t=317s반응형'데이터 엔지니어링 > Hive' 카테고리의 다른 글
[Hive] Merge문 이해하기 (0) 2022.10.26 [Hive] Hive에서 Transaction이란?(component, 제약조건, delta폴더, staging 폴더, insert, update, delete) (0) 2022.10.11 [Hive] Partition이란?(add 추가, drop 삭제, show partitions 조회, partitions) (2) 2022.10.11 [Hive]Create table Location 알아보기 (0) 2022.10.06 [Hive] Hive query - Bucketing table 알아보기 (0) 2022.10.06